Определение клубочков на изображениях ткани почек человека средствами сегментации [тренировка модели]
Данное состязание проводилось на Kaggle (https://www.kaggle.com/c/hubmap-kidney-segmentation/overview), все данные можно найти там. В настоящей работе представлены не самые оптимальные методы методы и конфигурации, но различие результата с наилучшим всего 1.3% достоверности. При этом не были проведены работы с данными (не использовались дополнительные и не корректировались доразмечались существующие). Задача состоит в следующем. Есть изображения почек, например, см. ниже

На изображениях необходимо найти клубочки:

В качестве метрики результата используется коэффициент Дайеса (Dice coefficient).
Фреймворком выступал Keras и библиотека сегментации segmentation_models (https://github.com/qubvel/segmentation_models). Входные данные задавались в tfrecord так, как показано здесь.
На Kaggle можно найти и блокноты, в которых подробно расписана работа по обучению и распознаванию, например:
- создание записей tfrecord (https://www.kaggle.com/wrrosa/hubmap-tf-with-tpu-efficientunet-512x512-tfrecs);
- тренировка (https://www.kaggle.com/wrrosa/hubmap-tf-with-tpu-efficientunet-512x512-train);
- распознавание (https://www.kaggle.com/wrrosa/hubmap-tf-with-tpu-efficientunet-512x512-subm).
В данной статье будет описана тренировка модели, предполагая, что tfrecords существуют, тем более, что уже было описано создание tfrecords.
Инициализация данных для обучения
Для обучения была выбрана модель Unet с Backbones efficientnetb5. Почему именно эта конфигурация? Unet в различных модификация очень хорошо работает на подобных медицинских задачах. А EfficientNet в качестве основы дает лучший результат. Почему именно EfficientNet b5. При обучении использовались изображения размером 512x512, а тут https://keras.io/examples/vision/image_classification_efficientnet_fine_tuning/ показано, что весовые коэффициенты модели b5 соответствуют разрешению 456x456, а b6 - 528x528. Т.е. наиболее близкие это b5 и b6. Конечно можно было попробовать разбить большое изображение мелкие 456x456, тем более там большие изображения для распознавания например 20000 на 20000 пикселей. Но у меня возникли проблемы с библиотекой - если вкратце, то за небольшое время не удалось заставить обучаться на 456x456, хотя в библиотеке предусмотрен ввод произвольного разрешения. Подобные ошибки я находил и в Интернете, но там в качестве решения все просто приводили изображения к кратному 2 виду.
Сначала вводятся в словарь глобальные параметры:
P = {}
P['EPOCHS'] = 60 # максимальное количество эпох
P['BACKBONE'] = 'efficientnetb5'
P['NFOLDS'] = 4 # количество обучаемых моделей
P['SEED'] = 0
P['VERBOSE'] = 1
P['DISPLAY_PLOT'] = True
P['BATCH_COE'] = 8 # коэффициент влияющий на batch
P['DIM'] = 512 # разрешение изображений
P['LR'] = 0.00025 #коэффициент для функции потерь
# сохранить параметры в файл
import yaml
with open(r'params.yaml', 'w') as file:
yaml.dump(P, file)
Затем импортируются библиотеки:
! pip install segmentation_models -q
%matplotlib inline
import os
os.environ['SM_FRAMEWORK'] = 'tf.keras'
import glob
import segmentation_models as sm
from segmentation_models.utils import set_trainable
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.utils import get_custom_objects
import cv2
import math
from kaggle_datasets import KaggleDatasets
print("Tensorflow version " + tf.__version__)
AUTO = tf.data.experimental.AUTOTUNE
Устанавливается стратегия для TPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver() # TPU detection
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
except ValueError: # no TPU found, detect GPUs
#strategy = tf.distribute.MirroredStrategy() # for GPU or multi-GPU machines
strategy = tf.distribute.get_strategy() # default strategy that works on CPU and single GPU
#strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # for clusters of multi-GPU machines
BATCH_SIZE = P['BATCH_COE'] * strategy.num_replicas_in_sync
print("Number of accelerators: ", strategy.num_replicas_in_sync)
print("BATCH_SIZE: ", str(BATCH_SIZE))
Путь до dataset:
GCS_PATH = KaggleDatasets().get_gcs_path('hubmap-of-2048512-images-with-test')
ALL_TRAINING_FILENAMES = tf.io.gfile.glob(GCS_PATH + '/train/*.tfrec')
ALL_TRAINING_FILENAMES
Результат:
['gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/0486052bb-104.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/095bf7a1f-196.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/1e2425f28-167.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/26dc41664-224.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/2f6ecfcdf-96.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/4ef6695ce-346.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/54f2eec69-86.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/8242609fa-230.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/aaa6a05cc-43.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/afa5e8098-325.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/b2dc8411c-63.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/b9a3865fc-236.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/c68fe75ea-338.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/cb2d976f4-268.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/d488c759a-61.tfrec',
'gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/e79de561c-99.tfrec']
В именах файлов есть информация о количестве изображений в каждом:
import re
def count_data_items(filenames):
n = [int(re.compile(r"-([0-9]*)\.").search(filename).group(1)) for filename in filenames]
return np.sum(n)
print(count_data_items(ALL_TRAINING_FILENAMES))
for f in ALL_TRAINING_FILENAMES:
print(f+":"+str(count_data_items([f])))
Результат:
2882
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/0486052bb-104.tfrec:104
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/095bf7a1f-196.tfrec:196
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/1e2425f28-167.tfrec:167
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/26dc41664-224.tfrec:224
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/2f6ecfcdf-96.tfrec:96
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/4ef6695ce-346.tfrec:346
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/54f2eec69-86.tfrec:86
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/8242609fa-230.tfrec:230
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/aaa6a05cc-43.tfrec:43
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/afa5e8098-325.tfrec:325
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/b2dc8411c-63.tfrec:63
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/b9a3865fc-236.tfrec:236
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/c68fe75ea-338.tfrec:338
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/cb2d976f4-268.tfrec:268
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/d488c759a-61.tfrec:61
gs://kds-9a75033927e9fa27642932632686eb39ceede221e322a066b73a3803/train/e79de561c-99.tfrec:99
Обучение
Функции для работы с данными представлены ниже. Используется аугументация для изменения изображений в каждой эпохе. Изображение вместе с маской случайным образов поворачивается (4 направления + отображения), изменяется яркость, контраст и насыщенность.
DIM = P['DIM']
def _parse_image_function(example_proto,augment = True):
image_feature_description = {
'image': tf.io.FixedLenFeature([, tf.string),
'mask': tf.io.FixedLenFeature([, tf.string)
}
single_example = tf.io.parse_single_example(example_proto, image_feature_description)
image = tf.reshape( tf.io.decode_raw(single_example['image'],out_type=np.dtype('uint8')), (DIM,DIM, 3))
mask = tf.reshape(tf.io.decode_raw(single_example['mask'],out_type='bool'),(DIM,DIM,1))
if augment: # https://www.kaggle.com/kool777/training-hubmap-eda-tf-keras-tpu
if tf.random.uniform(()) > 0.5:
image = tf.image.flip_left_right(image)
mask = tf.image.flip_left_right(mask)
if tf.random.uniform(()) > 0.4:
image = tf.image.flip_up_down(image)
mask = tf.image.flip_up_down(mask)
rot = tf.random.uniform([, 0, 1.0, dtype=tf.float32)
if rot > 0.25:
k_= int(rot/0.25)
image = tf.image.rot90(image, k=k_)
mask = tf.image.rot90(mask, k=k_)
if tf.random.uniform(()) > 0.45:
image = tf.image.random_saturation(image, 0.6, 1.4)
if tf.random.uniform(()) > 0.45:
image = tf.image.random_contrast(image, 0.7, 1.3)
if tf.random.uniform(()) > 0.45:
image = tf.image.random_brightness(image, 0.7, 1.3)
return tf.cast(image, tf.float32),tf.cast(mask, tf.float32)
def load_dataset(filenames, ordered=False):
ignore_order = tf.data.Options()
if not ordered:
ignore_order.experimental_deterministic = False
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTO)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(_parse_image_function, num_parallel_calls=AUTO)
return dataset
def get_training_dataset():
dataset = load_dataset(TRAINING_FILENAMES)
dataset = dataset.repeat()
dataset = dataset.shuffle(128, seed = P['SEED'])
dataset = dataset.batch(BATCH_SIZE,drop_remainder=True)
dataset = dataset.prefetch(AUTO)
return dataset
def get_validation_dataset(ordered=True):
dataset = load_dataset(VALIDATION_FILENAMES, ordered=ordered)
dataset = dataset.batch(BATCH_SIZE,drop_remainder=True)
#dataset = dataset.cache()
dataset = dataset.prefetch(AUTO)
return dataset
Метрика для обучения:
# https://tensorlayer.readthedocs.io/en/latest/_modules/tensorlayer/cost.html#dice_coe
def dice_coe(output, target, axis = None, smooth=1e-10):
output = tf.dtypes.cast( tf.math.greater(output, 0.5), tf. float32 )
target = tf.dtypes.cast( tf.math.greater(target, 0.5), tf. float32 )
inse = tf.reduce_sum(output * target, axis=axis)
l = tf.reduce_sum(output, axis=axis)
r = tf.reduce_sum(target, axis=axis)
dice = (2. * inse + smooth) / (l + r + smooth)
dice = tf.reduce_mean(dice, name='dice_coe')
return dice
Цикл обучения 4-х моделей:
fold = KFold(n_splits=P['NFOLDS'], shuffle=True, random_state=P['SEED'])
for fold,(tr_idx, val_idx) in enumerate(fold.split(ALL_TRAINING_FILENAMES)):
print('#'*35); print('############ FOLD ',fold+1,' #############'); print('#'*35);
print(f'Image Size: {DIM}, Batch Size: {BATCH_SIZE}')
# CREATE TRAIN AND VALIDATION SUBSETS
TRAINING_FILENAMES = [ALL_TRAINING_FILENAMES[fi] for fi in tr_idx]
VALIDATION_FILENAMES = [ALL_TRAINING_FILENAMES[fi] for fi in val_idx]
STEPS_PER_EPOCH = count_data_items(TRAINING_FILENAMES) // BATCH_SIZE
STEPS_PER_EPOCH =int(STEPS_PER_EPOCH *1)
print(TRAINING_FILENAMES)
print(VALIDATION_FILENAMES)
# BUILD MODEL
K.clear_session()
with strategy.scope():
model = sm.Unet(P['BACKBONE'], encoder_weights='imagenet')#, encoder_freeze=True)
loss = sm.losses.DiceLoss(beta=1)
model.compile(optimizer = tf.keras.optimizers.Adam(lr = P['LR']),
#model.compile(optimizer = tf.keras.optimizers.SGD(learning_rate = 0.2),
#loss = tf.keras.losses.BinaryCrossentropy(),#'focal_tversky',
loss = loss,
metrics=[dice_coe,'accuracy'])
# CALLBACKS
checkpoint = tf.keras.callbacks.ModelCheckpoint('/kaggle/working/model-fold-%i.h5'%fold,
verbose=P['VERBOSE'],monitor='val_dice_coe',patience = 15,
mode='max',save_best_only=True)
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_dice_coe',mode = 'max', patience=15, restore_best_weights=True)
reduce = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=8, min_lr=0.00001)
#reduce = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=8, min_lr=0.045)
'''
print('Pre train model...')
model.fit(get_training_dataset(), epochs=4,
steps_per_epoch = STEPS_PER_EPOCH,
callbacks = [checkpoint, reduce,early_stop],
validation_data = get_validation_dataset(),
verbose=P['VERBOSE'] )
# release all layers for training
set_trainable(model,recompile=False) # set all layers trainable and recompile model
model.compile(optimizer = tf.keras.optimizers.Adam(lr = 0.0002),
loss = tf.keras.losses.BinaryCrossentropy(),
metrics=[dice_coe,'accuracy'])
'''
print('Training Model...')
history = model.fit(
get_training_dataset(),
epochs = P['EPOCHS'],
steps_per_epoch = STEPS_PER_EPOCH,
callbacks = [checkpoint, reduce,early_stop],
validation_data = get_validation_dataset(),
verbose=P['VERBOSE']
)
# PLOT TRAINING
# https://www.kaggle.com/cdeotte/triple-stratified-kfold-with-tfrecords
if P['DISPLAY_PLOT']:
plt.figure(figsize=(15,5))
n_e = np.arange(len(history.history['dice_coe']))
plt.plot(n_e,history.history['dice_coe'],'-o',label='Train tversky',color='#ff7f0e')
plt.plot(n_e,history.history['val_dice_coe'],'-o',label='Val tversky',color='#1f77b4')
x = np.argmax( history.history['val_dice_coe'] ); y = np.max( history.history['val_dice_coe'] )
xdist = plt.xlim()[1] - plt.xlim()[0]; ydist = plt.ylim()[1] - plt.ylim()[0]
plt.scatter(x,y,s=200,color='#1f77b4'); plt.text(x-0.03*xdist,y-0.13*ydist,'max dice_coe\n%.2f'%y,size=14)
plt.ylabel('dice_coe',size=14); plt.xlabel('Epoch',size=14)
plt.legend(loc=2)
plt2 = plt.gca().twinx()
plt2.plot(n_e,history.history['loss'],'-o',label='Train Loss',color='#2ca02c')
plt2.plot(n_e,history.history['val_loss'],'-o',label='Val Loss',color='#d62728')
x = np.argmin( history.history['val_loss'] ); y = np.min( history.history['val_loss'] )
ydist = plt.ylim()[1] - plt.ylim()[0]
plt.scatter(x,y,s=200,color='#d62728'); plt.text(x-0.03*xdist,y+0.05*ydist,'min loss',size=14)
plt.ylabel('Loss',size=14)
plt.legend(loc=3)
plt.show()
В начале цикла создаются тренировочные и проверочные выборки, устанавливается количество шагов в эпохе. Создание модели происходит здесь: model = sm.Unet(P['BACKBONE'], encoder_weights='imagenet'), если там указать encoder_freeze=True, то это будет обозначать, что часть весов будут заморожены во время обучения (информацию об этом можно почитать в описании библиотеки). Это делается на первых шагах для pre-train, который в данном случае не помог и закомментирован. Зачем это делается? Чтобы на начальном этапе, когда градиент высокий, заданные веса, полученные на imagenet, не были полностью изменены.
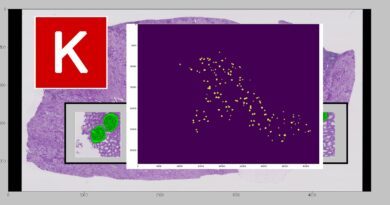
Функция потерь использована DiceLoss, а оптимизация - Adam. После обучения будут выданы такие интересные картинки:




Картинки получаются в конце каждого этапа и иллюстрирую ход обучения. Сохранение модели происходит в точках с максимальны значением метрики.
В следующей статье будет показано, как распознавать большие изображения с использованием данных моделей. Следующая статья