GeM Pooling и Image Retrieval
Слой GeM Pooling и его использование.
Материалы:
В задаче Image Retrieval осуществляется поиск подходящего изображения по большой базе изображений. В отличии от задачи классификации изображений здесь не используются метки (например, есть автомобиль, нет автомобиля), а поиск идет по какому-либо признаку (цвету, текстуре, форме и т. д.).
Идея состоит в том, чтобы извлечь глобальные и локальные функции из изображения и выполнить сопоставление/сходство изображения на основе этих извлеченных векторов. Как правило, представление изображения в виде вектора так же просто, как извлечение выходных данных из CNN непосредственно перед слоем объединения. Наконец, получить сходство изображений так же просто, как выполнить скалярное произведение между этими векторными представлениями, и похожие изображения имеют более высокое значение скалярного произведения, тогда как непохожие изображения имеют меньшие значения скалярного произведения.
Сложность заключается в наличии подходящих/точных векторных представлений для каждого изображения. Для этого можно обучить CNN выполнять классификацию изображений, а затем извлекать представления изображений из этой обученной модели. Собственно за тем нужно обучить сеть так, чтобы при наличии двух одинаковых объектов (например, автомобиль) на двух изображениях сеть выдавала 1, а для разных - 0. Но первоначально эти данные нужно пометить, а это довольно дорого, если размечать с помощью человека.
В статье авторы отказываются от необходимости вручную аннотировать данные или делать какие-либо предположения относительно обучающего набора данных. По сути, больше нет необходимости в метках изображений для поиска похожих изображений. Раньше смотрели на метки изображений и передавали модели два изображения с метками собак и обучали ее говорить, что эти два изображения являются совпадающей парой. Авторы устраняют необходимость в метках изображений для поиска похожих или непохожих изображений с помощью конвейера SfM: Мы достигаем этого, используя геометрию и положения камеры из 3D-моделей, автоматически реконструированных с помощью конвейера структуры из движения (SfM). Современный конвейер поиска SfM принимает неупорядоченную коллекцию изображений в качестве входных данных и пытается построить все возможные трехмерные модели.

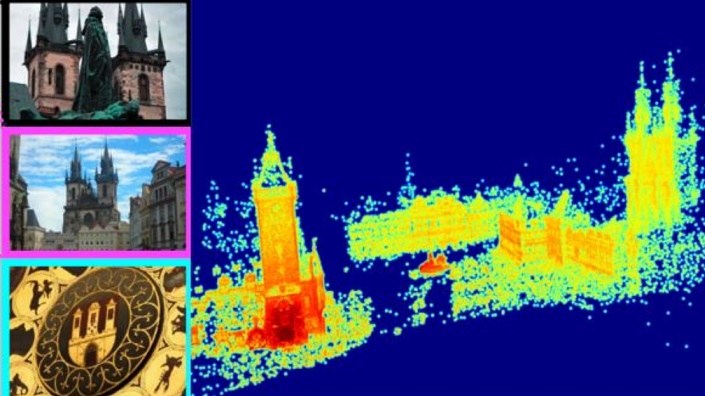
Типичный процесс реконструкции выглядит примерно так:

Т.е. можно реконструировать подробные 3D-модели из неупорядоченных коллекций фотографий. Это делается с помощью локальной пространственной верификации. Используя этот метод, можно найти похожие изображения и непохожие изображения без необходимости использования меток изображений.
Авторы использовали следующую архитектуру модели обучения с Contrastive Loss:

Можно сначала получить векторное представление изображения, получив выходные данные от CNN непосредственно перед слоем объединения. Затем авторы выполняют предложенную операцию GeM Pooling, чтобы уменьшить размерность, выполнить нормализацию и, наконец, конечным результатом является дескриптор изображения.
Какие возможные преимущества может иметь GeM Pooling по сравнению с Max/Average Pooling?
Авторы сообщают, что при обучении сети с использованием Siamese Learning и GeM Pooling неявные соответствия между изображениями улучшаются после тонкой настройки.
Учитывая входное изображение, выход CNN представляет собой трехмерный тензор формы K x H x W, где K - количество каналов, H относится к высоте карты объектов, а W относится к ширине карты объектов. Если Xk представляет собой активацию карты пространственных объектов H x W, то сеть состоит из K таких карт объектов. Виды Pooling:
- Max Pooling. для каждой карты объектов Xk мы берем максимальное значение, чтобы получить длинное векторное представление изображения длиной K.
- Average Pooling. для каждой карты объектов Xk мы берем среднее значение, чтобы получить длинное векторное представление изображения длиной K.
- GeM Pooling является обучаемым. Можно либо исправить гиперпараметр метода pk, либо обучить его с помощью обратного распространения в рамках стандартного процесса обучения модели.
GeM Pooling:

Реализация GeM Pooling в Pytorch:
class GeM(nn.Module):
def __init__(self, p=3, eps=1e-6):
super(GeM,self).__init__()
self.p = nn.Parameter(torch.ones(1)*p)
self.eps = eps
def forward(self, x):
return self.gem(x, p=self.p, eps=self.eps)
def gem(self, x, p=3, eps=1e-6):
return F.avg_pool2d(x.clamp(min=eps).pow(p), (x.size(-2), x.size(-1))).pow(1./p)
def __repr__(self):
return self.__class__.__name__ + '(' + 'p=' + '{:.4f}'.format(self.p.data.tolist()[0]) + ', ' + 'eps=' + str(self.eps) + ')'
Автор провел простой эксперимент, чтобы сравнить GeM с Average Pooling для задачи классификации питомцев и обнаружил, что пулы GeM и Average Pooling имеют сопоставимую точность.

