MobileBERT
BERT является массивной моделью, требующей значительных ресурсов, как для обучения, так и для конечного распознавания. Естественно, как и в случае с другими моделями сразу же возникла идея пожертвовать небольшой эффективностью с целью значительного увеличения быстродействия и возможности использования на устройствах с меньшими ресурсами. Т.е. сделать «урезанные» версии модели, к которым относятся TinyBERT и MobileBERT.
Теоретическую информацию о MobileBERT можно найти в работе:
https://www.aclweb.org/anthology/2020.acl-main.195.pdf
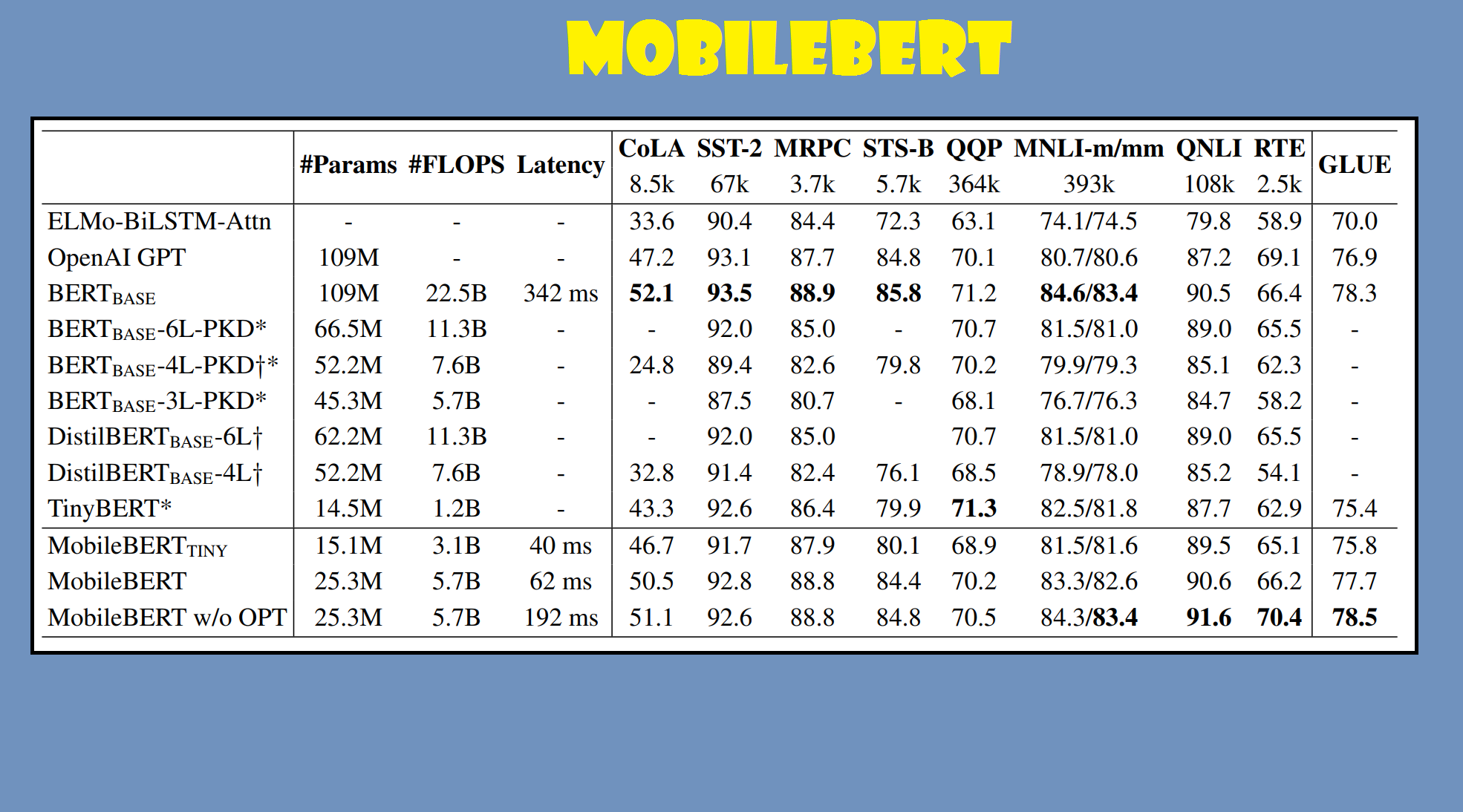
Авторы тестируют MobileBERT на задачах General Language Understanding Evaluation (GLUE) (см. работу Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.) и обнаружили, что для данных задач эта модель даже лучше базовой модели BERT

То же самое относится и к задаче SQuAD.

Авторы делают следующие выводы:
Можно с уверенностью заключить, что можно создать модель, которая будет одновременно эффективной и быстрой на устройствах с ограниченными ресурсами.
MobileBERT-tiny обеспечивает немного лучшую производительность по сравнению с TinyBERT. Однако это становится еще более впечатляющим, если учесть, как TinyBERT был настроен для задач GLUE. Т.е., BERT-базу учителя TinyBERT необходимо было отрегулировать, прежде чем ее знания можно было преобразовать в TinyBERT! В случае MobileBERT дело обстоит иначе.
Интерфейс по работе MobileBERT есть здесь:
https://huggingface.co/transformers/model_doc/mobilebert.html
В GoogleColab достаточно просто проверяется его работоспособность:
Установка:
Загрузка и инициализация моделей:
tensor([[1191032., 1201238.]], grad_fn=<ViewBackward>)
tensor([[0., 1.]], grad_fn=<SoftmaxBackward>)
Где 1 показывает, что answer_2 наиболее вероятный ответ. Но не стоит радоваться, поскольку небольшие изменения приведут к противоположному результату.