ConvNeXt V2: Совместное проектирование и масштабирование ConvNet с маскированными автоэнкодерами
ConvNeXt V2 - это новое семейство моделей, основанное на полностью свёрточном каркасе автокодировщика с масками (FCMAE) и новом уровне глобальной нормализации отклика (GRN), который можно добавить в архитектуру ConvNeXt для усиления межканальной конкуренции функций.
Статья: https://arxiv.org/pdf/2301.00808.pdf
GitHub: https://github.com/facebookresearch/ConvNeXt-V2
Модель ConvNeXt V2 работает значительно лучше, чем предыдущая версия, в широком диапазоне размеров моделей, что видно по следующему графику:

Видно, что модель достигает одни из наибольших показателей точности на наборе данных ImageNet для задачи классификации из современных моделей.
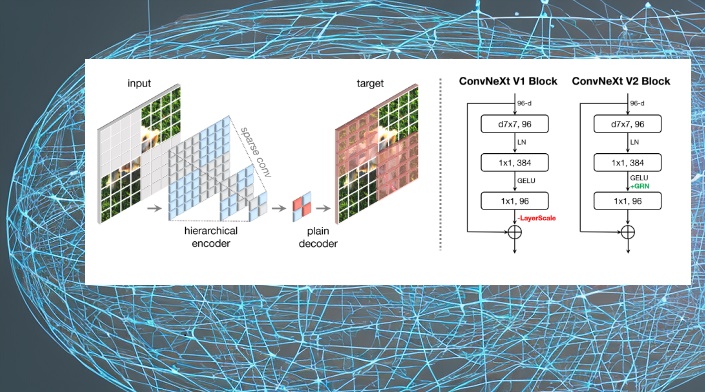
Основной особенностью модели является полностью свёрточный маскированный автоэнкодер (FCMAE), который состоит из разреженного кодера ConvNeXt на основе свертки и облегченного блочного декодера ConvNeXt. В целом архитектура автоэнкодера асимметрична. Кодер обрабатывает только видимые пиксели, а декодер реконструирует изображение, используя закодированные пиксели и маркеры маски. Потери рассчитываются только на замаскированной области. Структура FCMAE:

Визуализируется карта активации для каждого функционального канала в виде маленьких квадратиков. Для наглядности отображено 64 канала в каждой визуализации. Модель ConvNeXt V1 страдает от проблемы коллапса функций, которая характеризуется наличием избыточных активаций (мертвых или насыщенных нейронов) в каналах. Чтобы решить эту проблему, представлен новый метод для повышения разнообразия функций во время обучения: слой глобальной нормализации ответов (GRN). Этот метод применяется к многомерным функциям в каждом блоке, что привело к разработке архитектуры ConvNeXt V2.
Визуализация активации функции:

В ConvNeXt V2 добавляется слой GRN после слоя MLP и удаляется LayerScale, поскольку он становится избыточным.
Конструкции блоков ConvNeXt:

По результатам тестирования на задаче классификации точность модели выше других:

Что показали эксперименты:
Был проведен гиперпараметрический анализ коэффициента маскирования для размера маски 32 × 32. Результаты, показанные на рисунке ниже, показывают, что коэффициент маскирования в диапазоне от 0,5 до 0,7 дает наилучшие результаты, а коэффициент маскирования составляет 0.6 обеспечивает максимальную производительность. Производительность модели снижается в двух крайних случаях: удаление или оставление 90% входной информации, хотя она более надежна, когда сохраняется больше информации.



