Современные технологии трекинга объектов на видео
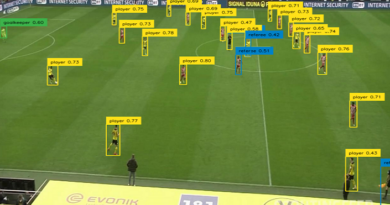
Трекинг (или слежение за объектами) является одним из важных механизмов современных систем видеонаблюдения, позволяющий подсчитывать объекты (люди, автомобили и др.) и вести учёт их перемещений.
Методы трекинга появились достаточно давно. Это, например, стандартный алгоритм Лукаса-Кенеди для слежения за точками, сопоставляющий точки в разных кадрах между собой.
Вопросы качества работы трекинга упираются в качество идентификации объектов на видео. Первоначально это были HOG-дескрипторы. Затем более качественные особенности - SURF, SIFT, FREAK и др.
С ростом использования глубоких нейронных сетей и видеокарт методы детектирования объектов значительно улучшились. Вот часть из них:
- YOLO. Простой и популярный метод детектирования объектов. Достаточно быстр, чтобы работать в реальном времени, сохраняя при этом достойное качество распознавания. YOLO разработан в Darknet, фреймворке нейронной сети с открытым исходным кодом
- Single Shot MultiBox Detector (SSD). Сверточная нейронная сеть пропускает входное изображение через серию сверточных слоев, попутно генерируя ограничивающие рамки кандидатов из разных масштабов.
- R-CNN. Алгоритм нейронной сети сканирует изображение с окнами разного масштаба и ищет соседние пиксели, которые имеют общие цвета и текстуры, а также учитывает условия освещения.
- Fast R-CNN. Одно большое улучшение по сравнению с R-CNN состоит в том, что вместо выполнения ~ 2000 прямых проходов для каждого предложения региона Fast R-CNN вычисляет сверточную карту характеристик для всего входного изображения за один прямой проход сети, что значительно ускоряет его.
- Faster R-CNN. Решает проблемы предыдущего метода. Он состоит из двух модулей: CNN, которая называется Region Proposal Network (RPN), и детектора Fast R-CNN. Два модуля объединены в единую сеть и проходят сквозное обучение.
- Mask R-CNN. Предназначена для сегментации экземпляров объектов. Сегментация экземпляра - это комбинация обнаружения объектов и семантической сегментации, что означает, что она выполняет как обнаружение всех объектов в изображении, так и сегментацию каждого экземпляра, отличая его от остальных экземпляров.
- RetinaNet. Это также одноступенчатая структура, такая как YOLO и SSD, которая предлагает высокую скоростью за худшую точность, чем двухэтапные структуры, такие как варианты R-CNN.
На базе этих новых методов детектирования объектов построены и методы трекинга:
- ROLO. Метод отслеживания одного объекта, который объединяет обнаружение объектов и рекуррентные нейронные сети. ROLO - это комбинация YOLO и LSTM.
- Deep SORT. Deep SORT улучшает SORT (алгоритмический подход к отслеживанию объектов), заменяя ассоциированную метрику новым обучением косинусной метрики, методом изучения пространства признаков, в котором косинусное сходство эффективно оптимизируется за счет репараметризации режима softmax.
- TrackR-CNN. TrackR-CNN был введен в качестве основы для решения задачи многообъектного отслеживания и сегментации (MOTS). Трекер создается путем интеграции трехмерных сверток.
- Tracktor++. Эта модель предсказывает положение объекта в следующем кадре, вычисляя регрессию ограничивающей рамки, без необходимости обучения или оптимизации данных отслеживания. Детектор объектов для Tracktor ++ - это обычный Faster R-CNN с 101-слойным ResNet и FPN, обученный на наборе данных обнаружения пешеходов MOT17Det.
- Joint Detection and Embedding (JDE). JDE использует Darknet-53 в качестве основы для получения карт характеристик входных данных в трех масштабах. После этого карты функций объединяются с использованием передискретизации и остаточных связей
Наиболее быстрыми являются методы ROLO, Deep SORT и JDE. Другие методы дают более высокое качество распознавания, но медленную работу, требуя при этом серьёзные ресурсы.
Довольно быстрым и умеренно точным является метод Deep SORT, поэтому попробуем его протестировать на каком-нибудь стандартном видео.
Один из примеров работы Deep Sort, работающий на базе Tensorflow представлен здесь:
https://github.com/Qidian213/deep_sort_yolov3
Будем использовать для тестирования Google Colab. Создадим новый блокнот, и скачаем репозиторий
Переходим в папку с проектом:
Качаем весовые коэффициенты для YOLO:
Перед запуском переключаемся на 1-ую версию Tensorflow:
Преобразуем модель в keras:
А дальше, перед запуском файла demo.py, его надо немного поправить. А именно:
Изменить строку с моделью на такую: model_filename = 'model_data/mars-small128.pb', поскольку именно такая была в репозитории, видимо автор забыл обновить. Закомментировать строки, которые работаю с выводом графического окна (на гугл колаб его нет):
#cv2.namedWindow("YOLO3_Deep_SORT", 0);
#cv2.resizeWindow('YOLO3_Deep_SORT', 1024, 768);
#cv2.imshow('YOLO3_Deep_SORT', frame)
#if cv2.waitKey(1) & 0xFF == ord('q'):
#break
#cv2.destroyAllWindows()
После этого, создаем папку test_video и папку output. В папку test_video помещаем файл test.avi - я взял стандартный из OpenCV.