Nlp. Вложения
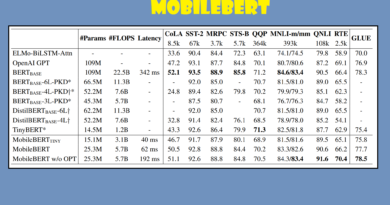
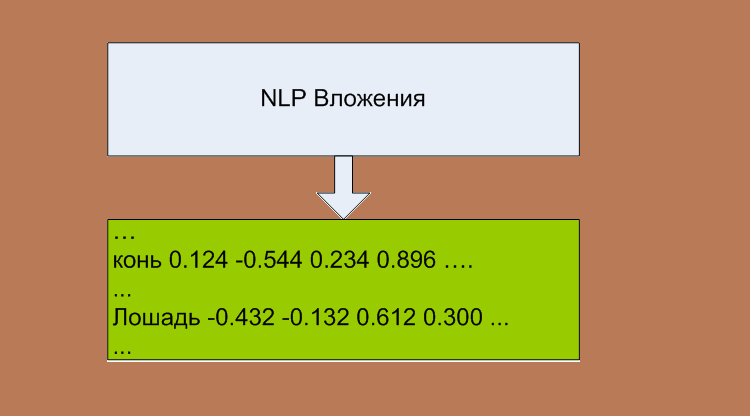
Для эффективного применения глубокого обучения в NLP необходимо представлять дискретные типы данных в виде плотных векторов. Если дискретные типы представляют собой слова, то векторное представление называется вложением слов.
Здесь считаем, что вы ставите эксперименты на Google Colab, поэтому сначала вам нужно установить annoy модуль.
Annoy( Приблизительные ближайшие соседи) - это библиотека C ++ с привязками Python для поиска точек в пространстве, близких к заданной точке запроса. Он также создает большие файловые структуры данных, доступные только для чтения, которые отображаются в память, поэтому многие процессы могут использовать одни и те же данные. Подробнее читайте здесь: https://pypi.org/project/annoy/
Проверяем подключение модуля
Если вдруг модуль не находится, то нужно перезагрузить ядро. Для работы со вложениями будет использован класс, код построен по книге с небольшими изменениями [Макмахан Б., Рао Д. - Знакомство с PyTorch 2020]. Код класса представлен ниже:
При инициализации на вход подаются word_to_int (отображение слова на индекс) и word_vectors (набор соответствий другим словам). Создается AnnoyIndex с Евклидовой метрикой для всех элементов.
Для загрузки данных используется метод класса load_from_file, который получает на вход имя файла. Собственно этот класс и формирует нужные отображения слов на индекс и вектора соответствий для данного слова.
Метод get_data возвращает для заданного слова вектор соответствий (вложений).
Метод get_closes возвращает ближайшие соседи к искомому слову.
Существуют различные наборы данных для вложений, один из них Glove. Для русского языка можно скачать здесь: https://www.kaggle.com/tunguz/russian-glove
Если вы не зарегистрированы ка Kaggle, то зарегистрируйтесь и получите токен для API. После чего можно загружать данные на Google Colab напрямую
Ну а после этого можете загружать данные
Команда выдаст примерно так:
Downloading russian-glove.zip to /content 99% 126M/127M [00:04<00:00, 27.3MB/s] 100% 127M/127M [00:04<00:00, 30.2MB/s]
Разархивируем:
Результат:
Archive: /content/russian-glove.zip inflating: multilingual_embeddings.ru
Инициализируем класс:
Проверяем работу:
Результат:
['собака', 'собаку', 'животное', 'местом', 'лошадь']
Ещё проверка
['смотреть', 'надо', 'говорить', 'должно']
Связи между вложениями слов
Главное во вложениях - это связи между словами. Т.е насколько в контексте разговора схожи слова. Например, часто в разговоре можно заменить кошку на собаку, т.к. речь идет о домашнем питомце. Существуют так называемые задачи на аналогии.
Например, есть три слова: лошадь, бежит, ворона
И нужно добавить четвертое: летит
Простейший способ решения следующим образом:
Результат:
мужчина : он :: женщина : ей
мужчина : он :: женщина : она
мужчина : он :: женщина : её
мужчина : он :: женщина : ее
Вроде работает, но выдалось несколько результатов. С английским языком проще, будет так:
man : he :: woman : she
Собственно это обусловлено большей сложностью языка, а также обученным файлов вложений
Вот еще вызовы и результаты
мужчина : муж :: женщина : мать
мужчина : муж :: женщина : мама
мужчина : муж :: женщина : подруга
мужчина : муж :: женщина : пациент
синий : цвет :: собака : сложный
синий : цвет :: собака : инструмент
синий : цвет :: собака : хороший
синий : цвет :: собака : рисунок
синий : цвет :: собака : объект
Как видим - для русского языка и конкретного файла вложений все не очень хорошо