Google BERT — внутреннее устройство
Оригинальная статья BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805
Введение. BERT (Bidirectional Encoder Representations from Transformers) - двунаправленная нейронная сеть кодировщик являющаяся state-of-the-art языковой моделью в задачах NLP. В данном посте представлено описание BERT, выполненное по материалу оригинальной статьи.
Откуда пошло. До BERT существовали две стратегии применения предварительно обученных языковых представлений для последующих задач: основанная на особенностях и точная настройка. Подход тонкой настройки, такой как Генеративный предварительно обученный трансформатор (OpenAI GPT) , вводит минимальные параметры для конкретной задачи и обучается на последующих задачах путем простой тонкой настройки всех предварительно обученных параметров. Основное ограничение заключается в том, что стандартные языковые модели однонаправлены. Например, в OpenAI GPT авторы используют левостороннюю архитектуру, в которой каждый токен может обращаться только к предыдущим токенам. По утверждению авторов, такой подход не оптимален и даже вреден в ряде случаев. Поэтому авторы предлагают двунаправленный подход к предварительной подготовке.
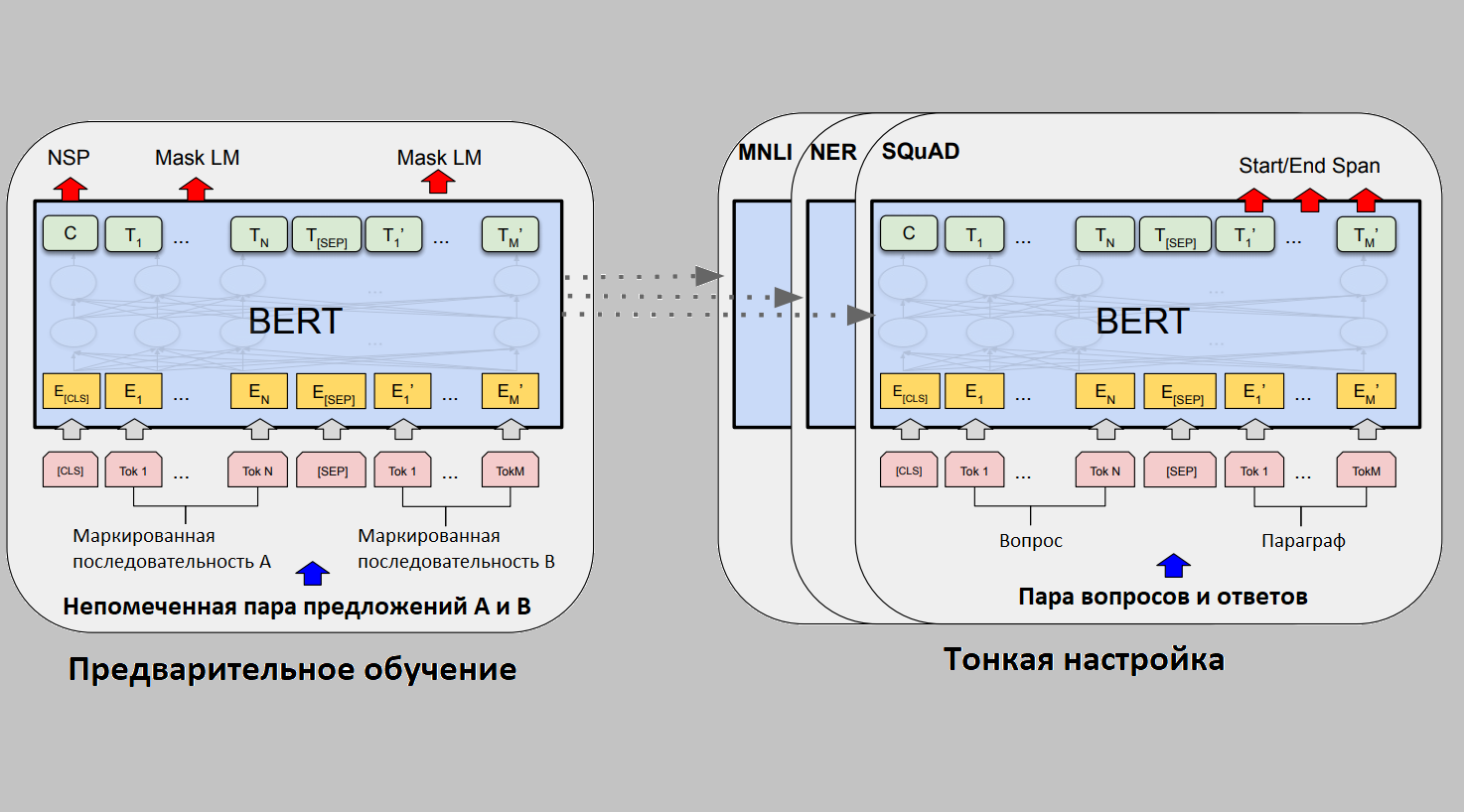
BERT. В структуре BERT есть два этапа: предварительное обучение и тонкая настройка. Во время предварительного обучения модель обучается на немаркированных данных с помощью различных предварительных задач. Для точной настройки модель BERT сначала инициализируется предварительно обученными параметрами, а все параметры настраиваются с использованием помеченных данных из последующих задач. У каждой последующей задачи есть отдельные точно настроенные модели, даже если они инициализируются с одинаковыми предварительно обученными параметрами. Ниже приведена картинка, иллюстрирующая данный пункт.

[CLS] - это специальный символ, добавляемый перед каждым примером ввода, а [SEP] - это специальный токен-разделитель (например, разделение вопросов / ответов). Здесь маркированная последовательность и маскированная последовательность может считаться синонимами.
Отличительной особенностью BERT является его унифицированная архитектура для решения различных задач. Архитектура модели BERT представляет собой многослойный двунаправленный кодировщик Transformer, основанный на исходной реализации, описанной в работе, указанной ниже и выпущенной в библиотеке tensor2tensor.
Оригинальная статья про Transformer (Attention Is All You Need ) тут https://arxiv.org/abs/1706.03762
Про трансформеры мы поговорим в другой раз, а в BERT использовались следующие параметры:
BERTBASE (L = 12, H = 768, A = 12, общие параметры = 110M) и BERTLARGE (L = 24, H = 1024, A = 16, общие параметры = 340M)
Здесь L-количество слоев (то есть блоков трансформера), H - скрытый размер, A - количество голов самовнимания.
BERT Transformer использует двунаправленное самовнимание, в то время как GPT Transformer использует ограниченное самовнимание, когда каждый токен может обращаться только к контексту слева от него.
Входное представление способно представлять как одно предложение, так и пару предложений (Вопрос, Ответ). «Предложение» может быть произвольным отрезком непрерывного текста, а не реальным лингвистическим предложением.
В BERT используются вложения WordPiece со словарём 30 000 токенов. Первым маркером каждой последовательности всегда является специальный маркер классификации ([CLS]). Конечное скрытое состояние, соответствующее этому токену, используется как представление совокупной последовательности для задач классификации. Пары предложений объединяются в одну последовательность. Различают предложения двумя способами. Сначала разделяют их специальным токеном ([SEP]). Во-вторых, мы добавляем заученное вложение к каждому токену, указывая, принадлежит ли он предложению A или предложению B. Входное вложение обозначается как E, последний скрытый вектор специального токена [CLS] как C,, а финальный скрытый вектор для i-го входного токена Ti . Для заданного токена его входное представление строится путем суммирования соответствующих вложений токена, сегмента и позиции. Визуализацию этой конструкции можно увидеть на рисунке ниже.

Предварительное обучение. BERT обучается двумя задачами.
- Task #1: Masked LM
- Task #2: Next Sentence Prediction (NSP)
В первом случае случайным образом маркируется (маскируется - задается маска) некоторый процент входных токенов, а затем предсказываются эти замаркированные токены. Прогнозируются только слова, которые заменены на [MASK] (замаскированные или маркированные). Во втором случае чтобы обучить модель, которая понимает отношения предложений, авторы предварительно обучают бинаризованной задаче прогнозирования следующего предложения, которая может быть тривиально сгенерирована из любого одноязычного корпуса. В частности, при выборе предложений A и B для каждого примера предварительного обучения, в 50% случаев B является фактическим следующим предложением, следующим за A (помеченным как IsNext), и в 50% случаев это случайное предложение из корпуса (помечено как NotNext).
Точная настройка. Тонкая настройка проста, поскольку механизм самовнимания в Transformer позволяет BERT моделировать множество последующих задач - независимо от того, связаны ли они с одним текстом или парами текста - путем замены соответствующих входов и выходов. Для приложений, использующих текстовые пары, распространенным шаблоном является независимое кодирование текстовых пар перед применением двунаправленного перекрестного внимания. место этого BERT использует механизм самовнимания для объединения этих двух этапов, поскольку кодирование конкатенированной текстовой пары с помощью самовнимания эффективно включает двунаправленное перекрестное внимание между двумя предложениями.
Для каждой задачи просто подключают входные и выходные данные для конкретных задач в BERT и полностью настраивают все параметры. На входе предложение A и предложение B из предварительного обучения аналогичны (1) парам предложений в перефразировке, (2) парам гипотеза-посылка в следствии, (3) парам вопрос-отрывок, отвечающим на вопрос, и (4) вырожденная пара текст-∅ в классификации текста или тегах последовательности. На выходе представления токенов подаются на выходной уровень для задач уровня токенов, таких как маркировка последовательностей или ответы на вопросы, а представление [CLS] подается на выходной уровень для классификации, такой как следствие или анализ тональности. По сравнению с предварительным обучением, тонкая настройка проводится относительно быстро.
Предварительно обученную модель и результаты тестов вы можете найти тут: